

امروزه استفاده از هوش مصنوعی و توسعه سیستم های هوشمند به دلیل اهمیت و کاربرد آن، و بازار داغ این علم، یادگیری هوش مصنوعی را جزو مهارت های مهم و اساسی عصر جدید قرار داده است و توجه افراد علاقمند به یادگیری بسیاری را به خود جلب کرده است. اما به دلیل گستردگی این علم، و پیچیده بودن یادگیری، نیاز به تعریف مسیر یادگیری هوش مصنوعی احساس میشود.
شرکت دانش بنیان فناوران گیتی افروز، توسعه دهنده برتر سیستم های مبتنی بر هوش مصنوعی و برگزار کننده دوره های جامع هوش مصنوعی، برای مخاطبان، نقشه راه کامل یادگیری هوش مصنوعی را معرفی میکند.
هوش مصنوعی و اهمیت آن
هوش مصنوعی علمی است که تلاش میکند با تقلید از هوش و روش فکر انسانی، سیستم های کامپیوتری را به فکر کردن، یادگیری ، تصمیم گیری و عمل قادر سازد. توانمندان در این زمینه با استفاده از الگوریم های کامپیوتری در محیطی پویا سعی در ایجاد چنین قابلیتی برای ماشین ها دارند. این توانایی به گونه ای است که استفاده از آن به طور قطع تحول عظیمی در آینده صنایع مختلف ایجاد خواهد کرد.
پایه فکر و اهمیت هوش مصنوعی بر تحلیل داده ها استوار است. امروزه انبوه داده های گردوری شده در حوزه های ممختلف به حدی است که انسان ها در یافته اند که برای تحلیل آنها نیاز به ذهنی سریع و بدون محدودیت دارند. در همین راستا، دانشمندان علوم داده هوش مصنوعی را به عنوان پاسخی به این نیاز روز افزون جامع بشری معرفی کرده و توسعه داده اند. افراد فعال در این زمینه اذعان دارند که هوش مصنوعی اگر چه هنوز قابلیت تفکر پیچیده انسانی را ندارد اما از مدودیت های آن فراتر رفته و قادر به انجام تحلیل و آنالیز سریع و دقیق است.
مسیر یادگیری هوش مصنوعی

هوش مصنوعی علمی گسترده است که به دو شاخه اصلی کلی مهندسی داده و علم داده تقسیم میشود. در ابتدای مسیر ابتدا لازم است که اصول پایه هوش مصنوعی فراگیرید. در ادامه مسیر میتوانید بنا به نیاز و یا علاقه خود یکی از دو مسیر گفته شده را ادامه دهید.
گام اول: مفاهیم پایه در یادگیری هوش مصنوعی
در ابتدای مسیر میبایست این اصول پایه را فراگیرید:
- مباحث مقدماتی شامل ریاضیات و اصول داده ها
- برنامه نویسی پایتون
- منابع جمعآوری داده
- آماده سازی داده ها و تحلیل اکتشافی
مباحث مقدماتی شامل ریاضیات و اصول داده ها
- متریک و اصول جبر خطی
- مفاهیم پایگاه داده
- پایگاه داده رابطه ای و غیر رابطه ای
- SQL + Joins (Inner, Outer, Cross, Theta Join)
- NoSQL
- داده های جدولی
- چهارچوب داده ها و سری ها
- ELT (Extract، Load، Transform)
- مقایسه BI و Analytics و Reporting
- فرمت های داده در هوش مصنوعی
- JSON
- XML
- CSV
- مفاهیم RegEx
برنامه نویسی پایتون
- مبانی پایتون
- عبارت ها و سینتکس
- متغیر ها
- ساختار داده
- توابع
- نصب پکیج ها
- اصول PEP8
- کتابخانه های مهم
- Numpy
- Pandas
- آشنایی با Virtual Environments
- مفاهیم Jupyter Notebooks / Lab
منابع جمع آوری داده
- داده کاوی
- وب اسکرپینگ
- بهترین دیتاست ها
- مفاهیم کگل (Kaggle)
تحلیل داده های اکتشافی و آماده سازی داده ها
- تحلیل مولفه اصلی (PCA)
- کاهش بعد
- نرمال سازی داده ها
- پاکسازی داده (Data Scrubbing)
- برآورد غیر اریب
- گروه بندی مقادیر گسسته
- استخراج ویژگی (Feature Extraction)
- حذف نویز
- سمپلینگ
گام دوم: انتخاب ادامه مسیر یادگیری هوش مصنوعی
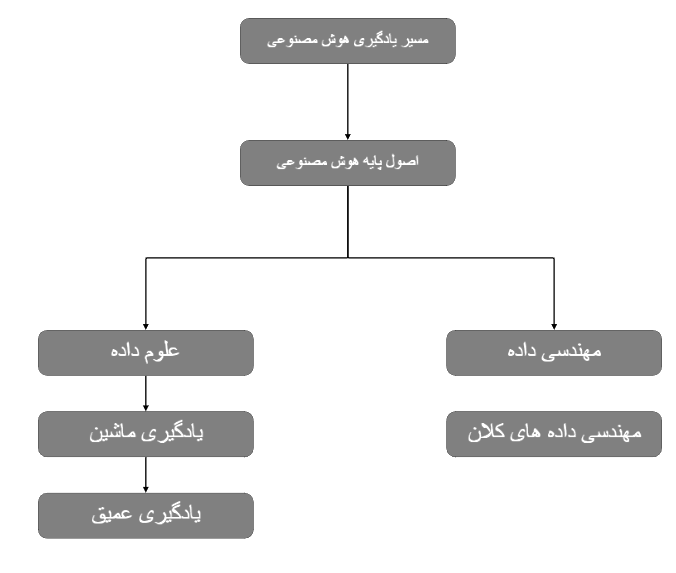
در این مرحله بنا به علاقه و یا نیازی که احساس می کنید یکی از دو مسیر موجود در هوش مصنوعی، علم داده و یا مهندسی داده، را ادامه میدهید.
علم داده
علم داده در واقع به مجموعهای از ابزارها، الگوریتمها و اصول یادگیری ماشین گفته می شود که هدف آن کشف کردن الگو از میان دادههای خام است. دانشمند داده در کنار تحلیل اکتشافی به منظور بررسی و کسب آگاهی، با الگوریتمهای پیچیده یادگیری ماشین به پیشبینی یک رویداد خاص در آینده میپردازد.
علاقمندان به ادامه مسیر میتوانند به آموزش «یادگیری ماشین» و «یادگیری عمیق» مشغول شوند.
مهندسی داده
مهندس داده پایپ لاین هایی (pipeline) طراحی می کند که از طریق آنها، دادهها به گونه ای ذخیره، تبدیل و منتقل شوند. این مسیر به شکلی است که در نهایت داده ها برای دانشمند داده آماده و کاربردی باشند. در واقع مهندسان داده، اطلاعات پایه و خام لازم برای کار دانشمندان داده را آماده میکنند.
علاقمندان به این مسیر میتوانند با تخصصی تر کردن آموزش خود،مهندس کلان داده شوند.
مهندسی داده
مسیر یادگیری مهندسی داده در هوش مصنوعی
- مروری بر فرمت داده ها
- داده کاوی
- منابع داده و اکتساب داده
- یکپارچه سازی داده
- تلفیق داده
- تبدیل و غنی سازی داده
- اپن رفاین (OpenRefine)
- بررسی داده ها
- استفاده از ELT
- استخر داده در برابر انبار داده
- داکرایز کردن اپلیکیشن (Dockerize)
مسیر یادگیری مهندسی کلان داده (Big Data Engineer)

معماری بیگ دیتا
- الگوهای معمای و بهترین روش های موجود
اصول مهندسی بیگ دیتا
- مقیاس بندی افقی در برابر مقیاس بندی عمودی
- پیاده سازی نگاشت کاهش (MapReduce)
- نام و نود های داده
- Data Replication
- Job & Task Tracker
ابزارهای بیگ دیتا
- بهترین فریم ورک های بیگ دیتا
- Hadoop
- HDFها
- بارگذاری اطلاعات با Sqoop and Pig
- Storm
- Spark
- RAPIDS (on GPU)
- Flume, Scribe
- انبار داده با Hive
- Elastic (EKL) Stack
- Avro
- Flink
- Dask
- Numba
- Onnx
- OpenVino
- MLFlow
- Kafka & KSQL
- دیتابیس ها
- Cassandra
- MongoDB, Neo4j
- انطباق پذیری
- ZooKeeper
- Kubernetes
- سرویس های ابری
- AWS SageMaker
- Google ML Engine
- Microsoft Azure, Machine Learning Studio
علم داده

مسیر یادگیری علوم داده در هوش مصنوعی
آمار
- آمار و احتمال
- توزیع های احتمالی
- نتایج تصادفی، متغیرفای تصادفی و سمپلینگ تصادفی
- احتمالات شریطی و قضیه بیز
- اسقلال آماری
- متغیرهای تصادفی IID
- توزیع مستمر (pdf)
- تابع توزیع تجمعی (cdf)
- تابع چگالی احتمال (pdf)
- تابع جرم احتمال (pmf)
- توزیع مستمر
- توزیع نرمال
- توزیع یکنواخت مداوم
- توزیع بتا
- توزیع دیریکله
- توزیع نمایی
- متغیر تصادفی و توزیع مربع کای
- توزیع یکنواخت گسسته
- توزیع یکنواخت گسسته
- توزیع دوجملهای
- متغیر تصادفی و توزیع چند جمله ای
- متغیر تصادفی و توزیع فوق هندسی
- توزیع پواسون
- توزیع هندسی
- مروری بر علم آمار و احتمال
- مقدار مورد انتظار و میانگین
- واریانس و توزیع استاندارد
- کوواریانس و همبستگی
- میانه و چارک
- دامنه بین چارکی
- درصد و چندک
- مد
- قوانین مهم
- قانون اعداد بزرگ
- قضیه حد مرکزی
- تخمین و برآورد
- برآورد درستنمایی بیشینه
- برآورد چگالی
- آزمون های فرض آماری
- مقدار احتمال (p-Value)
- آزمون مربع کای
- آزمون F
- آزمون t
- فاصله اطمینان (Confidence interval)
- متد مونت کارلو
مصورسازی دادهها
- آشنایی با نمودارها
- مصور سازی در پایتون
- کتابخانه Matplotlib
- پکیج ggplot2
- کتابخانه Bokeh
- کتابخانه seaborn
- کتابخانه ipyvolume برای مصورسازی سهبعدی دادهها
- وب
- Vega-Lite
- D3.js
- داشبورد
- Dash
- هوش تجاری
- آموزش tableau
- آموزش PowerBI
یادگیری ماشین
مسیر یادگیری «یادگیری ماشین» در هوش مصنوعی
مفاهیم پایه
- مفاهیم، ورودی ها و ویژگی های یادگیری ماشین
- متغیرهای طبقه بندی شده
- متغیرهای ترتیبی
- متغیرهای عددی
- توابع هزینه و نزول گرادیان
- بیش برازش (Overfitting)، کم برازش (Underfitting)
- داده های آموزش، اعتبار سنجی و آزمون
- صحت (Precision) و حساسیت (Recall)
- تعصب و واریانس
- Lift
روش ها یادگیری ماشین
- یادگیری نظارت شده (Supervised Learning)
- یادگیری بدون ناظر (Unsupervised Learning)
- خوشه بندی (clustering)
- خوشه بندی سلسله مراتبی (Hierarchical Clustering)
- خوشه بندی k میانگین (k-means Clustering)
- DBSCAN
- HDBSCAN
- Fuzzy C-Means
- Mean Shift
- روش «تجمیعی» (Agglomerative)
- OPTICS
- استخراج قانون وابستگی (association rule mining)
- الگوریتم اپریوری (Apriori Algorithm)
- ECLAT Algorithm
- FP Trees
- کاهش ابعاد (Dimensionality Reduction)
- تحلیل مولفه اساسی (PCA) یا (Principal Component Analysis)
- Random Projection
- NMF
- T-SNE
- UMAP
- خوشه بندی (clustering)
- یادگیری جمعی (ensemble learning)
- Boosting
- Bagging
- Stacking
- یادگیری تقویتی (Reinforcement Learning)
- Q-Learning
موارد کاربردی
- تجزیه و تحلیل احساسات (Sentiment Analysis)
- فیلترینگ مشارکتی (collaborative filtering)
- برچسب گذاری (Tagging)
- پیش بینی (Prediction)
ابزار یادگیری ماشین
- scikit-learn
- spacy (NLP)
یادگیری عمیق

مسیر یادگیری «یادگیری عمیق» در هوش مصنوعی
شبکههای عصبی مصنوعی (Neural Networks)
- آشنایی با شبکه های عصبی مصنوعی
- توابع زیان (Loss Function)
- توابع فعالساز (Activation Functions)
- Weight Initialization
- Vanishing / Exploding
معماری در یادگیری عمیق
- شبکه عصبی پیشخور ( Feedforward Neural Network )
- خودرمزگذارها (Autoencoder)
- شبکه عصبی پیچشی (Convolutional Neural Networks)
- لایه ادغام (Pooling Layer)
- شبکه عصبی بازگشتی (Recurrent Neural Networks)
- شبکه عصبی LSTM
- GRUs
- مدل Transformer
- Encoder
- Decoder
- Scaled dot-product attention
- شبکه عصبی Siamese
- شبکه های مولد تخاصمی (Generative Adversarial Networks)
- NEAT
- Residual neural network
آموزش
- Optimizers
- SGD
- Momentum
- Adam
- AdaGrad
- Adadelta
- Nadam
- RMSProp
- Learning rate schedule
- الگوریتم BatchNormalization
- Batch Size Effects
- نظم دهی ( Regularization )
- Early Stopping
- Dropout
- Parameter Penalties
- Data Augmentation
- Adversarial Training
- Multi-task learning
- یادگیری انتقال (Transfer Learning)
- Curriculum Learning
ابزار یادگیری عمیق
- کتابخانه های مهم
- آشنایی با Tensorflow
- آشنایی با Pytorch
- آشنایی با TensorBoard
- آشنایی با MLFlow
مباحث پیشرفته در یادگیری عمیق
- بهینه سازی مدل
- عصارهگیری از دانش یا (knowledge distillation)
- مبانی جستجوی معماری عصبی (NAS)
- کوانتیزاسیون (Quantization)